Alpha Risk: See Type I error.
Alternative Hypothesis: The hypothesis is obtained if the null hypothesis is rejected. It is denoted by Ha.
Analysis Of Variance (ANOVA): A hypothesis test for analyzing continuous data decides whether the means of three or more datasets are statistically different.
Attribute (or Discrete) Data: Data which cannot be treated as continuous and is usually subdivided into ordinal (e.g. counts), nominal and binary (e.g. go/no-go information) data.
Average: Of a sample (x-bar) is the sum of all the responses divided by the sample size.
Beta Risk: See Type II error.
Bimodal Distribution: A frequency distribution with two peaks. Usually, an indication of samples from two processes is incorrectly analyzed as a single process.
Binomial Distribution: A trial only has two possible outcomes (yes/no, pass/fail, heads/tails); one result has probability p and the other probability q = 1-p, the probability that the outcomes represented by p occur x times in n trials is given by binomial distribution.
Central Limit Theorem: If samples of size n are drawn from a population and the values of x are calculated for each sample, the shape of the distribution is found to approach a normal distribution for sufficiently large n.
Allows one to use the assumption of a normal distribution when dealing with x. The definition of sufficiently large depends on the population’s distribution, and what range of x is being considered; for practical purposes, the most straightforward approach may be to take several samples of the desired size and see if their means are normally distributed. If not, the sample size should be increased—one of the most important concepts is at the heart of inferential statistics.
Chi-Square: The test statistic is used when testing the null hypothesis of independence in a contingency table or when testing the null hypothesis of a data set following a prescribed distribution. (Chi-Square Distribution: The distribution of chi-square statistics.)
Coefficient of Determination (R2): The square of the sample correlation coefficient, a measure of the part of the variable that its linear relationship with a variable can explain; it represents the strength of a model. (1 – R2) *100% is the percentage of noise in the data not accounted for by the model.
Coefficient Of Variation (CV): Defined as the standard deviation divided by the mean (s/X-bar). It is the relative measure of the variability of a random variable.
E.g. a standard deviation of 10 microns would be extremely small in the production of bolts with a nominal length of 2 inches but extremely high for the variation in line widths on a chip whose mean width is 5 microns.
Confidence Interval: Range within which a parameter of a population (e.g. mean, standard deviation) may be expected to fall, based on a measurement, with some specified confidence level or confidence coefficient.
Confidence Limits: End points of the interval about the sample statistic that is believed to include the population parameter, with a specified confidence coefficient.
Continuous Data: Data which can be subdivided into ever-smaller increments.
Correlation Coefficient (r): A number between -1 and 1 indicates the degree of the linear relationship between two sets of numbers.
Degrees of Freedom: A parameter in the t, F, and x2 distributions. A measure of the amount of information available for estimating population variance; s2. It is the number of independent observations minus the number of parameters estimated.
Discrete Data: See Attribute Data.
Exponential Distribution: A probability distribution mathematically described by an exponential function. One application describes the probability that a product survives a long time in service under the assumption that the likelihood of a product failing in any small time interval is independent of time.
F Statistic: A test statistic used to compare the variance from two normal populations. (F Distribution: Distribution of F-statistics.)
Frequency Distribution: A set of all the various values that individual observations may have and the frequency of their occurrence in the sample or population.
Goodness-Of-Fit: Any measure of how well a data set matches a proposed distribution. Chi-square is the most common measure for frequency distributions.
A simple visual inspection of a histogram is a less quantitative but equally valid way to determine the goodness of fit.
Hypothesis Tests, Alternative: If the null hypothesis is disproved, the hypothesis is accepted. The choice of the alternative hypothesis will determine whether one- or two-tail tests are appropriate.
Hypothesis Tests, Null: The hypothesis tested in tests of significance is that there is no difference (null) between the population of the sample and the specified population (or between the populations associated with each sample). The null hypothesis can never be proved true. However, it can be untrue with a specified risk of error; the null hypothesis can show a difference between the populations. If not disproved, one may surmise that it is true. (It may be that there is insufficient power to prove the existence of a difference rather than no difference at all; that is, the sample size may be too small. By specifying the minimum difference that one wants to detect and P, the risk of failing to notice a difference of this size, the actual sample size required, however, can be determined.)
Hypothesis Tests: A procedure whereby one of two mutually exclusive and exhaustive statements about a population parameter is concluded. Information from a sample is used to infer something about a population from which the sample was drawn.
Kurtosis: A measure of the shape of a distribution. A positive value indicates that the distribution has longer tails than the normal distribution (platykurtosis), while a negative value indicates that the distribution has shorter tails (leptokurtosis). For the normal distribution, the kurtosis is 0.
Mean: The average of a set of values. We usually use x to denote a sample mean, using the Greek letter μ to represent a population mean.
Median: The number in the middle when all observations are ranked in magnitude.
Mode: The number in a set that occurs the most frequently.
Normal Distribution: Symmetric distribution is characterized by a smooth, bell-shaped curve.
p-Value: The probability of making a Type I error; the probability of H0 being true. This value arrives from the data itself. It also supplies the exact level of significance of a hypothesis test.
Poisson Distribution: A probability distribution for the number of occurrences per unit interval (time or space), where l = average number of occurrences per interval is the only parameter. The Poisson distribution approximates the binomial distribution for the case where n is large, and p is small. l = (np).
Population: A set or collection of objects or individuals. It can also be the corresponding set of values, which measure a particular characteristic of a group of objects or individuals.
Probability Distribution: The assignment of probabilities to all possible outcomes from an experiment. It is usually portrayed through a table, graph, or formula.
Probability: Measure the likelihood of a given event occurring. It takes on values between 0 and 1 inclusive, with 1 being the particular event and 0, meaning there is relatively no chance of the event occurring. How probabilities are assigned is another matter. The relative frequency approach to assigning probabilities is one of the most common.
Random Sampling: A commonly used sampling technique in which sample units are selected so that 0 combinations of n units under consideration have an equal chance of being chosen as the sample.
R: Pearson product movement coefficient of correlation.
Residual: The difference between an observed value and a predicted value.
Regression: A statistical technique for determining the best mathematical expression describing the functional relationship between one response and one or more independent variables.
Sample Size: The number of elements or units in a sample.
Sample: A group of units, portion of the material, or observations taken from a more significant collection of units, the quantity of material, or observations that serves to provide information that may be used as a basis for deciding on the larger quantity.
Skewness: A measure of the symmetry of a distribution. A positive value indicates that the distribution has a greater tendency to tail to the right (positively skewed or skewed to the right), and a negative value indicates a greater tendency of the distribution to tail to the left (negatively skewed or skewed to the left). Skewness is 0 for a normal distribution.
Standard Deviation (s, s): A mathematical quantity that describes response variability. It equals the square root of variance. The standard deviation of a sample (s) is used to estimate the standard deviation of a population (s).
Standardized Normal Distribution: A normal distribution or a random variable having a mean and standard deviation of 0 and 1, respectively. It is denoted by the symbol Z and is also called the Z distribution.
Statistical Sampling: Statistical process for determining the characteristics of a population from the characteristics of a sample.
T Distribution: A symmetric, bell-shaped distribution resembles the standardized normal (or Z) distribution, but it typically has more area in its tails than the Z distribution. That is, it has more significant variability than the Z distribution.
T Test: A population hypothesis test means when small samples are involved.
Test Statistic: A single value which combines the evidence obtained from sample data. The p-value in a hypothesis test is directly related to this value.
Type I Error: An incorrect decision to reject something (such as a statistical hypothesis or many products) when it is acceptable.
Type II Error: An incorrect decision to accept something when it is unacceptable.
Variance: A measure of variability in a data set or population. It is the square of the standard deviation.
Z Distribution: See Standardised Normal Distribution.
Z Value: A standardized value formed by subtracting the mean from each measurement and then dividing this difference by the standard deviation.











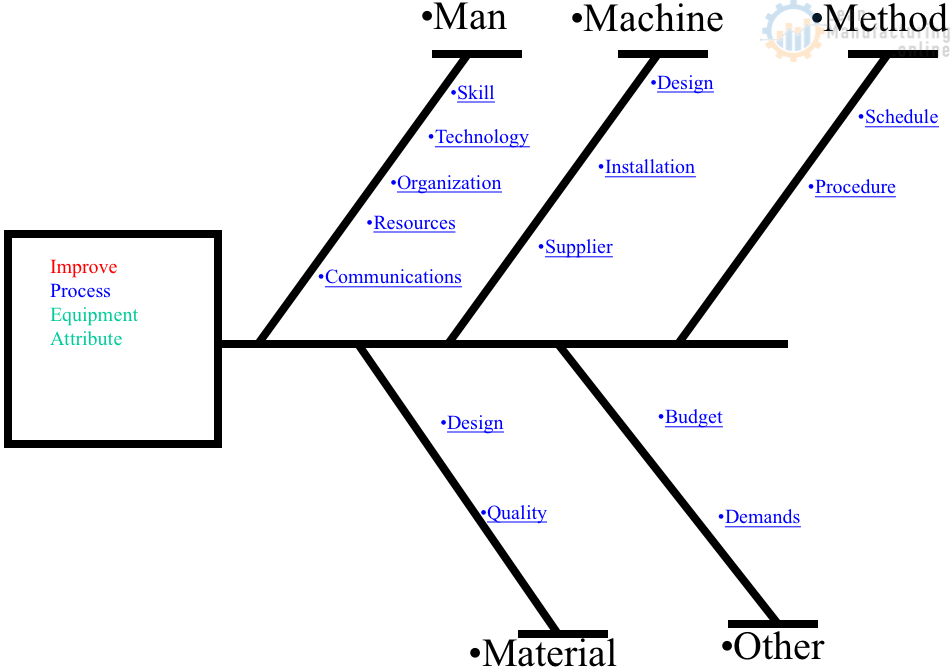
4M Analysis Process
The purpose of this procedure is to define the steps to do a 4M …


